ML Introduction
Preprocessing
Regression
Classification
Data Transformation in Machine Learning

Data Transformation
Data Transformation
Data Transformation is use to convert data into a suitable format for modeling.
Data Transformation Steps
Step 1: Normalization & Standardization (scaling)
- Normalization and Standardization (scaling): Adjusting the range of data to ensure that no feature dominates due to its scale.
- Normalization and Standardization common techniques include: Min-Max Scaling, and Standardization (Scaling)
- Min-Max Scaling: Rescaling features to a range between 0 and 1.
- Standardization: Transforming features to have a mean of 0 and a standard deviation of 1.
Step 2: Encoding Categorical Variables
- Encoding Categorical Variables: Converting categorical variables into numerical values.
- Encoding Categorical Variables common techniques include: Label Encoding and One-Hot Encoding.
- Label Encoding: Assigning a unique integer to each category.
- One-Hot Encoding: Creating binary columns for each category.
Step3: Log Transformation
- Log Transformation: Applying logarithmic transformation to skewed data to make it more normal distribution-like.
Normalization & Standardization (scaling)
Normalization & Standardization (scaling) are essential preprocessing steps in machine learning, ensuring that features are on a comparable scale.
This can lead to improved model performance and faster convergence during training.
Normalization
- Normalization also known as min-max scaling.
- Normalization transforms data to fit within a specific range, usually [0, 1] or [-1, 1].
- This technique rescales the feature with a minimum of 0 and a maximum of 1.
Normalization Formula
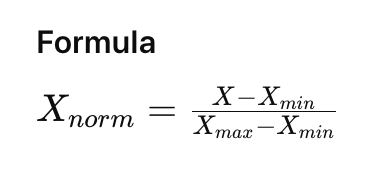
Where,
X is the original value,
X_min is the minimum value of the feature, and
X_max is the maximum value of the feature.
Normalization with Python Array Example
Apply the Normalization on the 2-D array using the fit_transform function.
import numpy as np
from sklearn.preprocessing import MinMaxScaler
data = np.array([
[1], [2], [3], [4], [5]
])
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
print(normalized_data)
[[0. ]
[0.25]
[0.5 ]
[0.75]
[1. ]]
After running, you can see all numeric values are converted range in between 0 to 1.
Normalization with Data Frame Example
You can also apply Normalization to the data frame, the steps are the same as we performed in the above example.
In this data frame, we apply Normalization on the price column.
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv("homeprices.csv")
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(df[["price"]])
df["new_price"] = normalized_data
df
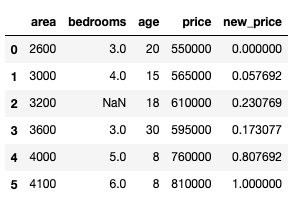
After running, you can see that all price column values range from 0 to 1.
Standardization / Scaling
- Scaling (or standardization) transforms data with a mean of 0 and a standard deviation of 1.
- This technique is useful when the features have different units or different distributions.
Standardization Formula
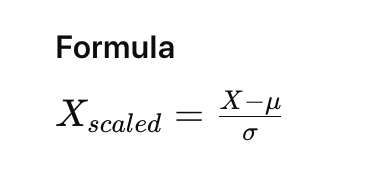
Where,
X is the original value,
μ (mu) is the mean of the feature, and
σ (sigma) is the standard deviation of the feature.
Standardization with Python Array Example
Apply the Standardization on the 2-D array using the fit_transform function.
import numpy as np
from sklearn.preprocessing import StandardScaler
data = np.array([
[1], [2], [3], [4], [5]
])
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
[[-1.41421356]
[-0.70710678]
[ 0. ]
[ 0.70710678]
[ 1.41421356]]
After running, all numeric values transformed into a mean of 0 and a standard deviation of 1.
Standardization with Data Frame Example
You can also apply Standardization to the data frame, the steps are the same as we performed in the above example.
In this data frame, we apply Standardization on the price column.
import pandas as pd
from sklearn.preprocessing import StandardScaler
df = pd.read_csv("homeprices.csv")
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df[["price"]])
df["new_price"] = scaled_data
df
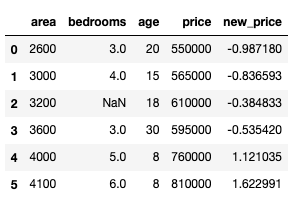
After running, you can see that all price column values range from a mean of 0 and a standard deviation of 1.